Sequencing
How to formulate a disassembly problem as a sequencing / decision making problem? Commonly studied in manufacturing, less in architecture. Challenge is how to augment existing strategies to describe problems in construction more aptly. Consider the intermediate bracing to a column and girder in the removal of this roof joist.
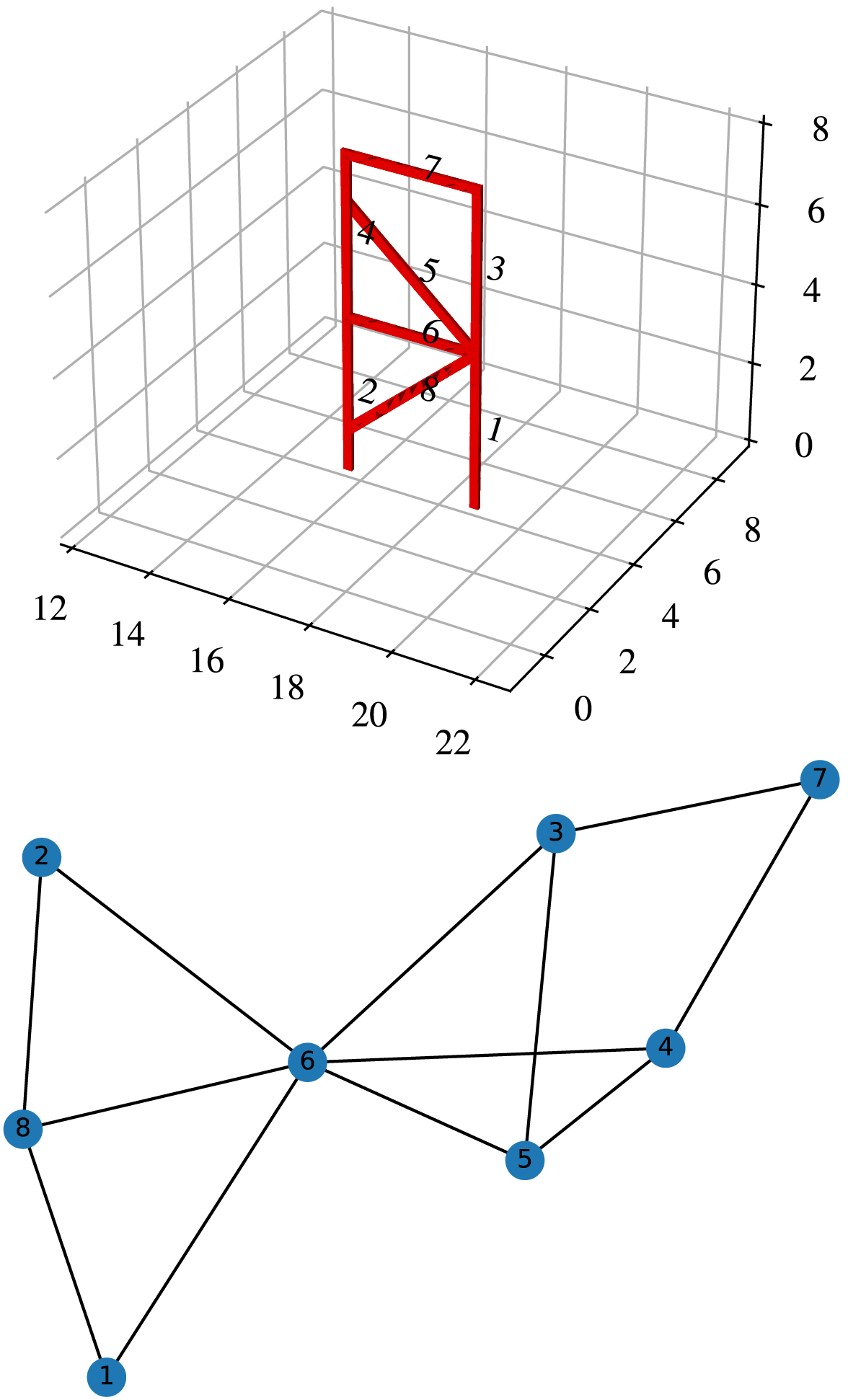
Assemblies can be represented with elements as nodes, and edges as connections. Here's a simple example. The graph hold topological information but not spatial information. Computing spatial relationships can be encoded in so called contact and constraint matrices. The algorithms to compute them are shown below. The disassembly sequence starts with a node, using some heuristic like the least number of connected parts, choose blocking elements until nothing is in the way, remove the node, and adjust the matrices.
Experiments:
More examples below to find bugs, geometric or logic, to learn how the algorithm scales with complexity of assembly and number of parts.
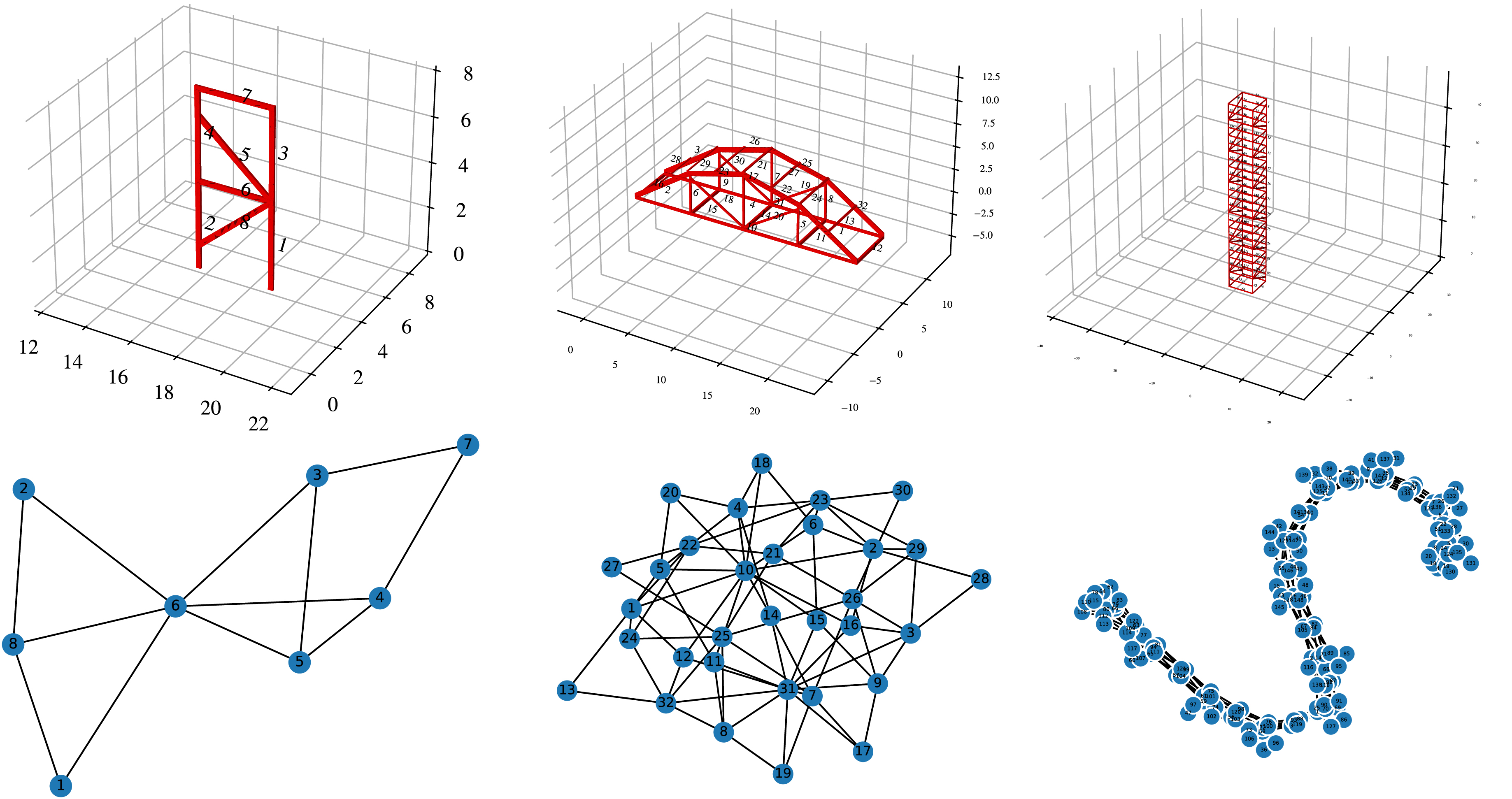
Time Complexity:
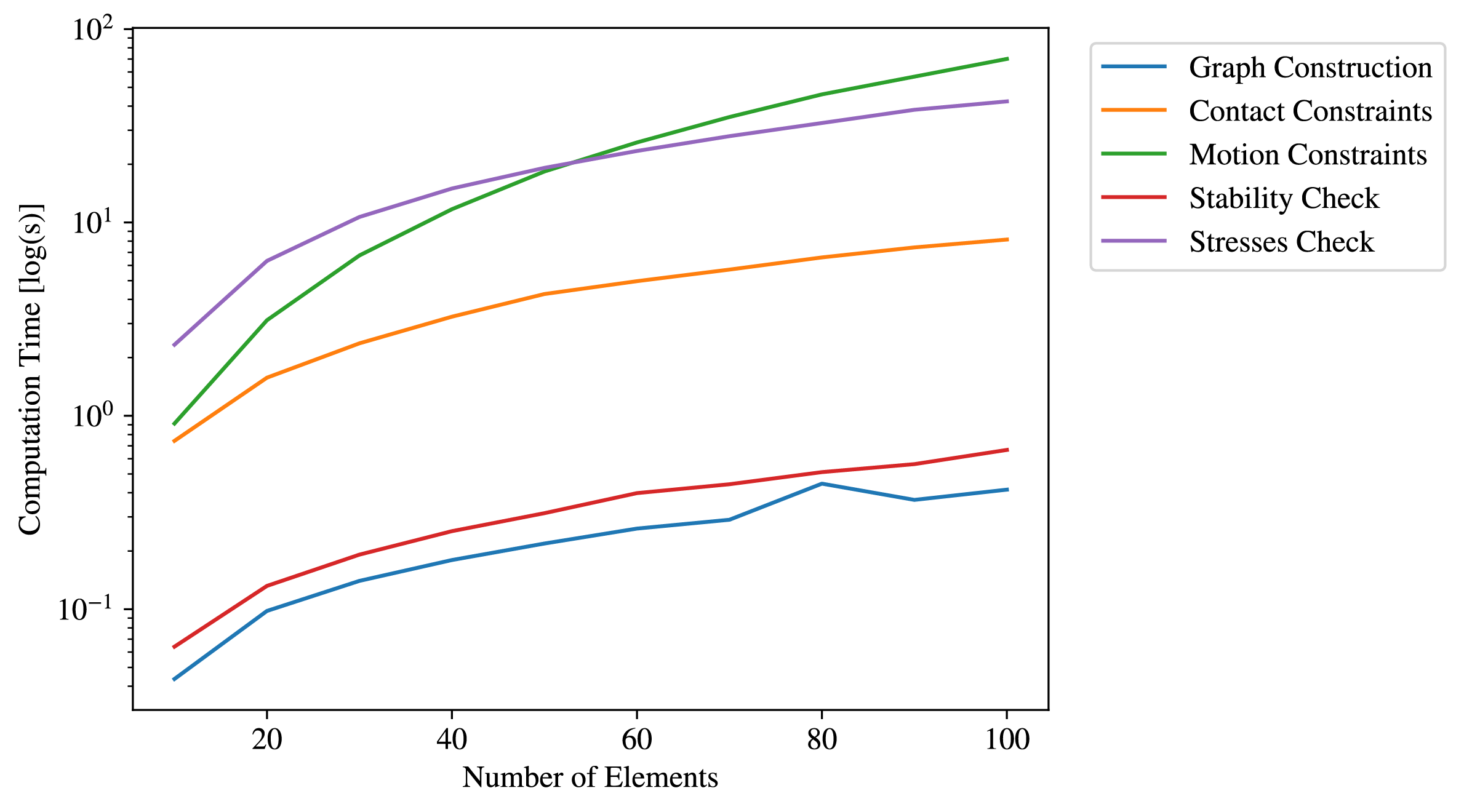
Checking stresses and motion constraints are bottlenecks. A different approach from voxel mapping and solving the PDE for linear elasticity would make things faster.